In der heutigen Welt steht Künstliche Intelligenz an der Spitze technologischer Innovation, wobei neuronale Netze in diesem Bereich eine zentrale Rolle spielen. Neuronale Netze, inspiriert von der biologischen Struktur des menschlichen Gehirns, sind leistungsstarke Rechenmodelle, die komplexe Probleme lösen können, indem sie nachahmen, wie Neuronen Informationen verarbeiten und übertragen. Anwendungen für neuronale Netze erstrecken sich über ein breites Spektrum von Branchen, darunter Bilderkennung, natürliche Sprachverarbeitung, selbstfahrende Autos und medizinische Diagnose, und verändern die Art und Weise, wie wir leben und arbeiten.
Angetrieben von meiner Leidenschaft für Technologie konnte ich es nicht lassen, das Potenzial neuronaler Netze und maschinellen Lernens zu erkunden. Diese Neugier veranlasste mich, tiefer in dieses Gebiet einzutauchen, um die Theorie und praktischen Anwendungen dieser Technologien besser zu verstehen. Zunächst las ich mehrere Artikel, die die grundlegenden Konzepte neuronaler Netze erläuterten, und nachdem ich theoretisches Wissen erworben hatte, beschloss ich, dieses Verständnis auf ein praktisches Projekt anzuwenden.
In diesem Artikel teile ich meine Erfahrungen mit neuronalen Netzen und konzentriere mich dabei auf das Projekt, das ich zur Erkennung handgeschriebener Ziffern von 0 bis 9 abgeschlossen habe.
Projektbeschreibung:
In diesem Projekt konzentrierte ich mich auf die Erkennung handgeschriebener Ziffern von 0 bis 9. Die Erkennung handgeschriebener Ziffern ist ein klassisches Problem im Bereich maschinelles Lernen und Computer Vision und dient als Einstiegspunkt für viele Enthusiasten, die ihre Reise in die Welt der neuronalen Netze beginnen.
Die verwendeten Tools und Technologien:
Zur Erstellung des neuronalen Netzes für mein Projekt zur Erkennung handgeschriebener Ziffern nutzte ich verschiedene Tools und Technologien, die die Entwicklung und Implementierung des Modells erleichterten. Nachfolgend ein Überblick über die wichtigsten Ressourcen, die ich im Verlauf des Projekts eingesetzt habe:
1. Programmiersprache:
Python war meine bevorzugte Programmiersprache, da sie im Bereich neuronaler Netze am weitesten verbreitet ist und daher umfangreiche Unterstützung für maschinelles Lernen und Datenmanipulationsbibliotheken bietet. Die weite Verbreitung von Python in der KI-Community stellt zudem eine Fülle von Online-Ressourcen und Tutorials zur Bewältigung verschiedener Herausforderungen sicher.
2. Der Datensatz – MNIST:
Für mein Projekt verwendete ich den MNIST-Datensatz (Modified National Institute of Standards and Technology). Er umfasst 70.000 Graustufenbilder handgeschriebener Ziffern, wobei jedes Bild 28 x 28 Pixel groß ist. Der Datensatz ist in 60.000 Trainingsbilder und 10.000 Testbilder unterteilt, was ein effektives Training und die Bewertung von Modellen für maschinelles Lernen ermöglicht. Jedes Bild im Datensatz ist mit der entsprechenden Ziffer beschriftet, die es darstellt, von 0 bis 9.
3. Frameworks:
Ich verwendete TensorFlow und Keras zum Aufbau und Training meines neuronalen Netzes. TensorFlow, entwickelt von Google Brain, ist eine Open-Source-Bibliothek für maschinelles Lernen, die eine flexible Plattform zur Erstellung verschiedener Arten von neuronalen Netzen bietet. Keras hingegen ist eine High-Level-API für neuronale Netze, die auf TensorFlow aufbaut. Sie vereinfacht den Aufbau und das Training neuronaler Netze, macht es für Einsteiger zugänglicher und ermöglicht schnelles Prototyping.
4. Bibliotheken und Pakete:
Für die Datenvisualisierung verwendete ich die Matplotlib-Bibliothek.
Die Modell-Architektur:
Die Architektur des neuronalen Netzes für das Projekt zur Erkennung handgeschriebener Ziffern wurde so konzipiert, dass die wesentlichen Merkmale der Eingangsbilder effektiv erfasst werden, während die Komplexität des Modells beherrschbar bleibt. Nachfolgend eine Beschreibung der verschiedenen Komponenten des Modells:
1. Eingabeschicht:
Die Eingabeschicht nimmt die 28 x 28 Pixel großen Graustufenbilder handgeschriebener Ziffern entgegen. Diese Bilder werden in einen 4D-Tensor mit den Dimensionen (batch_size, 28, 28, 1) umgeformt, um die Anforderungen der Faltungsschichten zu erfüllen.
2. Faltungsschichten:
Das Modell verfügt über drei Faltungsschichten mit Filtergrößen von 3 x 3 und unterschiedlicher Anzahl von Filtern (32, 64 bzw. 64). Diese Schichten lernen, wichtige Merkmale aus den Bildern zu extrahieren, wie Kanten, Kurven und Muster. In jeder dieser Schichten wird eine Rectified Linear Unit (ReLU)-Aktivierungsfunktion verwendet, um Nichtlinearität in das Modell einzuführen.
3. Pooling-Schichten:
Nach der ersten und zweiten Faltungsschicht werden zwei MaxPooling-Schichten mit einer Pool-Größe von 2 x 2 hinzugefügt. Diese Schichten reduzieren die räumlichen Dimensionen der Eingabe und helfen dem Modell, sich auf die relevantesten Merkmale zu konzentrieren, während sie gleichzeitig die Rechenkomplexität reduzieren und Overfitting verhindern.
4. Flatten-Schicht:
Eine Flatten-Schicht ist enthalten, um die Ausgabe der letzten Faltungsschicht in ein 1D-Array umzuwandeln und sie für die Eingabe in die vollständig verbundenen Schichten vorzubereiten.
5. Vollständig verbundene (Dense) Schichten:
Das Modell hat zwei vollständig verbundene Schichten. Die erste Schicht hat 64 Knoten und verwendet eine ReLU-Aktivierungsfunktion, um die extrahierten Merkmale weiter zu verarbeiten. Die zweite Schicht hat 10 Knoten (einer für jede Ziffer von 0 bis 9) und verwendet eine Softmax-Aktivierungsfunktion, um Wahrscheinlichkeitsverteilungen für die Ziffernklassifizierungen zu erzeugen.
6. Optimierungsalgorithmus und Verlustfunktion:
Zum Training des Modells wird ein “Adam”-Optimierer verwendet, ein adaptiver Lernraten-Optimierungsalgorithmus, der sich gut für das Training tiefer neuronaler Netze eignet. Die im Modell verwendete Verlustfunktion ist “categorical_crossentropy”, die ideal für Mehrklassen-Klassifizierungsprobleme ist. Diese Verlustfunktion berechnet den Fehler zwischen der vorhergesagten Wahrscheinlichkeitsverteilung und den tatsächlichen One-Hot-kodierten Labels und leitet das Modell an, seine Gewichte anzupassen, um den Fehler zu minimieren.

Training und Testen des Modells:
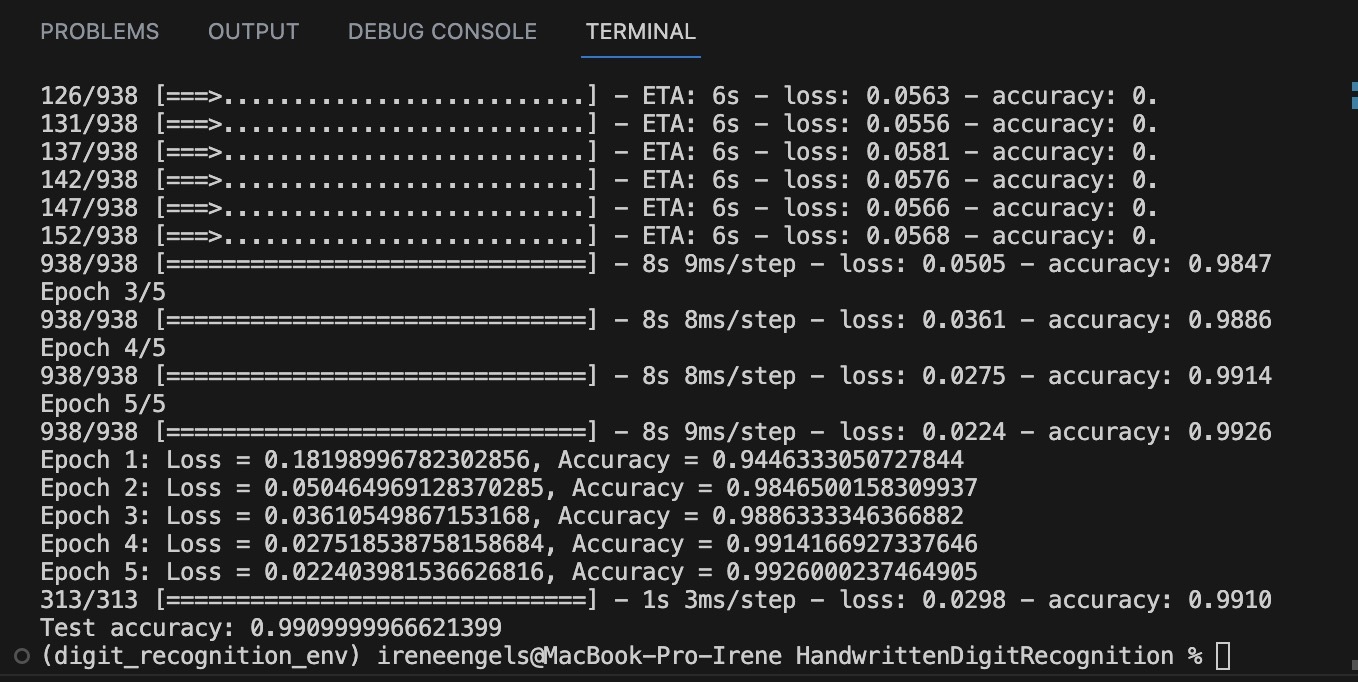
Nachdem die Daten vorbereitet und die Modellarchitektur entworfen worden war, bestand der nächste Schritt darin, das Modell zu trainieren. Beim Trainingsprozess werden dem Modell die Trainingsdaten gezeigt und es kann iterativ Vorhersagen treffen. Für jede Vorhersage berechnet das Modell mithilfe einer mathematischen Funktion, der sogenannten “Verlustfunktion”, wie weit es vom tatsächlichen Ergebnis abweicht. Anschließend passt es seine internen Parameter so an, dass es beim nächsten Mal etwas weniger falsch liegt.
In diesem Fall trainierte ich das Modell über 5 Epochen. Eine Epoche ist ein vollständiger Durchlauf über den gesamten Trainingsdatensatz. Jede Epoche bestand aus 938 Schritten, entsprechend den 938 Batches mit je 64 Bildern in den Trainingsdaten.
Hier eine Zusammenfassung des Trainingsfortschritts:
- Epoche 1: Verlust = 0,1783, Genauigkeit = 94,57 %
- Epoche 2: Verlust = 0,0516, Genauigkeit = 98,40 %
- Epoche 3: Verlust = 0,0373, Genauigkeit = 98,82 %
- Epoche 4: Verlust = 0,0282, Genauigkeit = 99,09 %
- Epoche 5: Verlust = 0,0228, Genauigkeit = 99,24 %
Wie zu sehen ist, nahm der Verlust des Modells mit jeder Epoche ab, was darauf hinweist, dass es mit jedem Durchlauf der Daten besser darin wurde, die korrekten Ziffernlabels vorherzusagen. Gleichzeitig stieg die Genauigkeit der Vorhersagen des Modells mit jeder Epoche.
Nach dem Training testete ich das Modell am Testdatensatz, um seine Leistung bei neuen, ungesehenen Daten zu bewerten. Der Verlust beim Testdatensatz betrug 0,0319, und das Modell erzielte eine Genauigkeit von 98,92 %. Diese hohe Genauigkeit bestätigt, dass das Modell effektiv gelernt hat, handgeschriebene Ziffern zu erkennen, und in der Lage war, gut von den Trainingsdaten auf ungesehene Daten im Testset zu generalisieren.
Das Training und Testen des Modells war eine entscheidende Phase des Projekts. Zu beobachten, wie das Modell aus den Daten lernte und seine Vorhersagen mit jeder Epoche verbesserte, war sowohl faszinierend als auch lohnend. Als Ergebnis meiner Bemühungen verfüge ich nun über ein Modell, das handgeschriebene Ziffern von 0 bis 9 präzise erkennen kann.
Zukünftige Nutzung und Bereitstellung des trainierten Modells:
Nachdem ein Modell zur erfolgreichen Erkennung handgeschriebener Ziffern aufgebaut und trainiert wurde, ist einer der lohnendsten nächsten Schritte die Anwendung dieses Modells in realen Szenarien. Die Vielseitigkeit von Modellen für maschinelles Lernen liegt in ihrer Fähigkeit, gespeichert, geteilt und auf verschiedenen Plattformen bereitgestellt zu werden, wodurch ihre Nutzbarkeit über die ursprüngliche Entwicklungsumgebung hinaus erweitert wird.
In TensorFlow können Sie das gesamte Modell im HDF5-Format oder im SavedModel-Format speichern. Letzteres ist umfassender und enthält einen TensorFlow-Checkpoint mit den Modellgewichten sowie die Modellarchitektur und die Optimizer-Konfiguration. Dies geschieht mit der Funktion model.save(). Sobald das Modell gespeichert ist, können Sie es in einem anderen Python-Skript (oder sogar auf einem anderen Computer) laden und für Vorhersagen, die Bewertung neuer Daten oder sogar das Fortsetzen des Trainings verwenden.
Die eigentliche Stärke des Speicherns von Modellen liegt jedoch in der Möglichkeit, sie in verschiedenen Anwendungen bereitzustellen. Sie können Ihr Modell beispielsweise in einer Android- oder iOS-Anwendung oder in einer Webanwendung einsetzen, sodass Benutzer direkt damit interagieren können. Dafür gibt es verschiedene Möglichkeiten.
Für Webanwendungen kann TensorFlow.js verwendet werden, um Modelle in einem Browser zu laden und auszuführen. TensorFlow.js bietet Hilfsmittel zum Speichern und Laden von Modellen direkt aus dem LocalStorage oder IndexedDB des Browsers. Modelle können auch von einem statischen HTTP/HTTPS-Server oder von Cloud-Speicherplattformen wie Google Cloud Storage bereitgestellt werden.
Für mobile Anwendungen ermöglicht TensorFlow Lite die Bereitstellung von TensorFlow-Modellen auf Mobil- und IoT-Geräten. Die Modelle sind leichtgewichtig und haben eine geringe Latenz, um maschinelles Lernen auf dem Gerät zu ermöglichen. Der TensorFlow-Lite-Konverter erstellt eine .tflite-Datei aus einem SavedModel.
Auf diese Weise kann das von mir für die Erkennung handgeschriebener Ziffern trainierte Modell gespeichert und dann in verschiedenen Kontexten eingesetzt werden – sei es eine Web-App, die handgeschriebene Notizen digitalisiert, oder eine mobile App, die die Kamera eines Geräts nutzt, um handgeschriebene Ziffern in Echtzeit zu erkennen. Die Möglichkeiten sind zahlreich und nur durch Vorstellungskraft und Einfallsreichtum begrenzt.
Verfasst von Iryna Engels.