בעולם של היום, בינה מלאכותית נמצאת בחזית החדשנות הטכנולוגית, כאשר רשתות נוירונים ממלאות תפקיד מרכזי בתחום זה. רשתות נוירונים, אשר נוצרו בהשראת המבנה הביולוגי של המוח האנושי, הן מודלים חישוביים עוצמתיים היכולים לפתור בעיות מורכבות באמצעות חיקוי האופן שבו נוירונים מעבדים ומעבירים מידע. יישומים של רשתות נוירונים משתרעים על מגוון רחב של תעשיות, כולל זיהוי תמונות, עיבוד שפה טבעית, רכבים אוטונומיים ואבחון רפואי, ומשנים את הדרך שבה אנו חיים ועובדים.
מתוך תשוקה לטכנולוגיה, לא יכולתי להתעלם מהפוטנציאל של רשתות נוירונים ולמידת מכונה. הסקרנות הזו הובילה אותי להעמיק בתחום, במטרה להבין טוב יותר את התיאוריה והיישומים המעשיים של טכנולוגיות אלו. כדי להתחיל, קראתי מספר מאמרים שהסבירו את המושגים הבסיסיים של רשתות נוירונים, ולאחר שרכשתי ידע תיאורטי מסוים, החלטתי ליישם את ההבנה הזו בפרויקט מעשי.
במאמר זה אשתף את הניסיון שלי עם רשתות נוירונים, תוך התמקדות בפרויקט שביצעתי לזיהוי ספרות בכתב יד מ-0 עד 9.
תיאור הפרויקט:
בפרויקט זה התמקדתי בזיהוי ספרות בכתב יד בטווח שבין 0 ל-9. זיהוי ספרות בכתב יד הוא בעיה קלאסית בתחום למידת המכונה וראיית המחשב, ומשמש כנקודת כניסה עבור רבים המתחילים את דרכם בעולם רשתות הנוירונים.
הכלים והטכנולוגיות:
כדי ליצור את רשת הנוירונים עבור פרויקט זיהוי הספרות בכתב היד שלי, השתמשתי במגוון כלים וטכנולוגיות שסייעו בפיתוח וביישום המודל. להלן סקירה של המשאבים המרכזיים בהם השתמשתי במהלך הפרויקט:
1. שפת תכנות:
בחרתי ב-Python משום שזו השפה הפופולרית ביותר בתחום רשתות הנוירונים, ולכן היא מספקת תמיכה רחבה בספריות ללמידת מכונה ולעיבוד נתונים. האימוץ הרחב של Python בקהילת ה-AI מבטיח גם שפע של משאבים ומדריכים אונליין להתמודדות עם אתגרים שונים.
2. מערך הנתונים – MNIST:
לפרויקט שלי השתמשתי במאגר הנתונים MNIST (Modified National Institute of Standards and Technology). המאגר כולל 70,000 תמונות בגווני אפור של ספרות בכתב יד, כאשר כל תמונה בגודל של 28×28 פיקסלים. המאגר מחולק ל-60,000 תמונות אימון ו-10,000 תמונות בדיקה, מה שמאפשר אימון והערכה יעילים של מודלים ללמידת מכונה. כל תמונה מסומנת עם הספרה המתאימה לה, בטווח שבין 0 ל-9.
3. Frameworks:
השתמשתי ב-TensorFlow וב-Keras לבניית ואימון רשת הנוירונים שלי. TensorFlow, שפותחה על ידי Google Brain, היא ספריית קוד פתוח ללמידת מכונה המספקת פלטפורמה גמישה ליצירת סוגים שונים של רשתות נוירונים. Keras, לעומת זאת, היא API ברמה גבוהה לרשתות נוירונים שפועל מעל TensorFlow. היא מפשטת את תהליך בניית ואימון הרשתות, הופכת אותו לנגיש יותר למתחילים ומאפשרת יצירת אבטיפוסים מהירה.
4. ספריות וחבילות:
לצורך ויזואליזציית הנתונים השתמשתי בספריית Matplotlib.
מודל ה-Architecture:
הארכיטקטורה של רשת הנוירונים עבור פרויקט זיהוי הספרות בכתב היד תוכננה כך שתלכוד בצורה יעילה את המאפיינים החשובים של תמונות הקלט, תוך שמירה על מורכבות מודל סבירה. להלן תיאור של רכיבי המודל השונים:
1. שכבת קלט:
שכבת הקלט מקבלת את תמונות הספרות בגווני אפור בגודל 28×28 פיקסלים. תמונות אלו עוברות עיצוב מחדש ל-tensor בארבעה ממדים בגודל (batch_size, 28, 28, 1) כדי להתאים לדרישות של שכבות הקונבולוציה.
2. שכבות קונבולוציה:
המודל כולל שלוש שכבות קונבולוציה עם פילטרים בגודל 3×3 ומספר משתנה של פילטרים (32, 64 ו-64 בהתאמה). שכבות אלו לומדות לחלץ מאפיינים חשובים מהתמונות, כגון קצוות, עקומות ודפוסים. בכל אחת מהשכבות נעשה שימוש בפונקציית האקטיבציה ReLU כדי להוסיף אי-ליניאריות למודל.
3. שכבות Pooling:
שתי שכבות MaxPooling בגודל 2×2 נוספו לאחר שכבות הקונבולוציה הראשונה והשנייה. שכבות אלו מצמצמות את הממדים המרחביים של הקלט, מסייעות למודל להתמקד במאפיינים הרלוונטיים ביותר, מפחיתות מורכבות חישובית ומונעות התאמת יתר (Overfitting).
4. שכבת Flatten:
שכבת Flatten ממירה את הפלט של שכבת הקונבולוציה האחרונה למערך חד-ממדי, כהכנה להזנה לשכבות המחוברות במלואן.
5. שכבות Fully Connected (Dense):
המודל כולל שתי שכבות Fully Connected. השכבה הראשונה כוללת 64 נוירונים ומשתמשת בפונקציית ReLU כדי לעבד עוד יותר את המאפיינים שחולצו. השכבה השנייה כוללת 10 נוירונים (אחד עבור כל ספרה מ-0 עד 9) ומשתמשת בפונקציית softmax כדי להפיק התפלגות הסתברויות עבור סיווג הספרות.
6. אלגוריתם אופטימיזציה ופונקציית Loss:
לצורך אימון המודל השתמשתי באופטימייזר 'adam', שהוא אלגוריתם אופטימיזציה עם קצב למידה אדפטיבי המתאים במיוחד לאימון רשתות נוירונים עמוקות. פונקציית ה-loss שנבחרה היא 'categorical_crossentropy', המתאימה לבעיות סיווג מרובות מחלקות. פונקציה זו מחשבת את השגיאה בין התפלגות ההסתברויות החזויה לבין התוויות האמיתיות המקודדות ב-One-Hot, ומנחה את המודל להתאים את המשקלים שלו כדי למזער את השגיאה.

אימון ובדיקת המודל:
לאחר הכנת הנתונים ותכנון ארכיטקטורת המודל, השלב הבא היה לאמן את המודל. תהליך האימון כולל הצגת נתוני האימון למודל ומתן אפשרות לבצע תחזיות באופן איטרטיבי. עבור כל תחזית, המודל מחשב עד כמה התחזית רחוקה מהתוצאה האמיתית באמצעות פונקציה מתמטית הנקראת "loss function". לאחר מכן הוא מתאים את הפרמטרים הפנימיים שלו כך שבפעם הבאה יהיה מעט מדויק יותר.
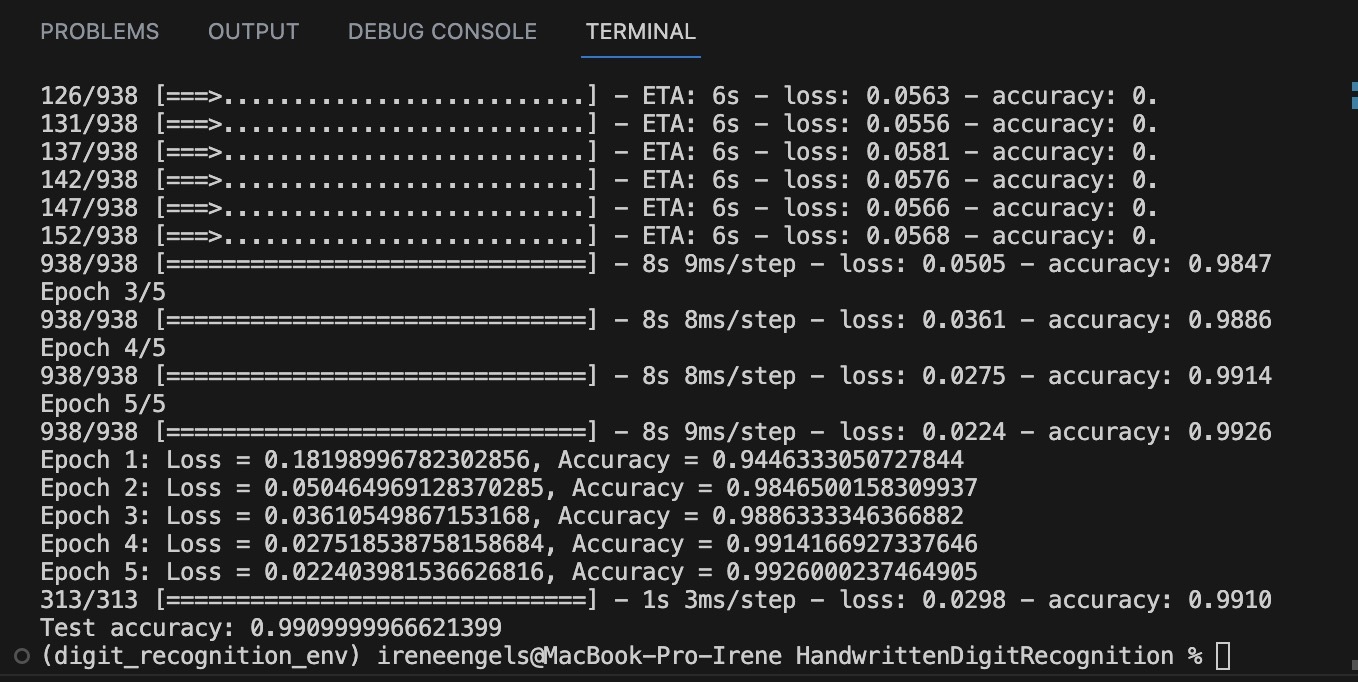
במקרה זה, אימנתי את המודל במשך 5 epochs. Epoch הוא מעבר מלא על כל מערך נתוני האימון. כל epoch כלל 938 צעדים, המתאימים ל-938 קבוצות של 64 תמונות כל אחת מתוך נתוני האימון.
להלן סיכום התקדמות האימון:
- Epoch 1: Loss = 0.1783, Accuracy = 94.57%
- Epoch 2: Loss = 0.0516, Accuracy = 98.40%
- Epoch 3: Loss = 0.0373, Accuracy = 98.82%
- Epoch 4: Loss = 0.0282, Accuracy = 99.09%
- Epoch 5: Loss = 0.0228, Accuracy = 99.24%
כפי שניתן לראות, ערך ה-loss של המודל ירד בכל epoch, מה שמעיד על כך שהוא השתפר בזיהוי הספרות הנכונות בכל מעבר על הנתונים. במקביל, דיוק התחזיות של המודל עלה עם כל epoch.
לאחר שהמודל אומן, בדקתי אותו על מערך נתוני הבדיקה כדי להעריך את ביצועיו על נתונים חדשים שלא נראו קודם. ה-loss על מערך הבדיקה היה 0.0319, והמודל השיג דיוק של 98.92%. דיוק גבוה זה מאשר שהמודל למד לזהות ספרות בכתב יד בצורה יעילה והצליח להכליל היטב מנתוני האימון לנתוני בדיקה חדשים.
אימון ובדיקת המודל היו שלב מרכזי בפרויקט. הצפייה בדרך שבה המודל למד מהנתונים ושיפר את התחזיות שלו בכל epoch הייתה מרתקת ומספקת. כתוצאה מהמאמצים שלי, יש לי כעת מודל שמסוגל לזהות במדויק ספרות בכתב יד מ-0 עד 9.
שימוש עתידי ופריסה של המודל המאומן:
לאחר שבניתי ואימנתי מודל שמזהה בהצלחה ספרות בכתב יד, אחד השלבים המתגמלים ביותר הוא יישום המודל בתרחישים אמיתיים. הכוח של מודלים ללמידת מכונה טמון ביכולת שלהם להישמר, להיות משותפים ולהיפרס בפלטפורמות שונות, וכך להרחיב את השימוש בהם מעבר לסביבה הראשונית שבה פותחו.
ב-TensorFlow ניתן לשמור את המודל כולו בפורמט HDF5 או בפורמט SavedModel. הפורמט השני מקיף יותר וכולל checkpoint של TensorFlow המכיל את משקלי המודל, ארכיטקטורת המודל והגדרות האופטימייזר. פעולה זו מתבצעת באמצעות הפונקציה model.save(). לאחר שמירת המודל, ניתן לטעון אותו בסקריפט Python אחר (או אפילו במחשב אחר) ולהשתמש בו לביצוע תחזיות, הערכה על נתונים חדשים או המשך אימון.
העוצמה האמיתית של שמירת מודלים היא היכולת לפרוס אותם ביישומים שונים. לדוגמה, ניתן להשתמש במודל באפליקציית Android או iOS, או באפליקציית Web, ולאפשר למשתמשים ליצור איתו אינטראקציה ישירה. קיימות דרכים רבות לעשות זאת.
עבור אפליקציות Web, ניתן להשתמש ב-TensorFlow.js כדי לטעון ולהריץ מודלים ישירות בדפדפן. TensorFlow.js מספק כלים לשמירה וטעינה של מודלים מ-LocalStorage או IndexedDB של הדפדפן. ניתן גם להגיש מודלים משרת HTTP/HTTPS סטטי או מפלטפורמות אחסון בענן כמו Google Cloud Storage.
עבור אפליקציות מובייל, TensorFlow Lite מאפשר לפרוס מודלי TensorFlow על מכשירי מובייל ו-IoT. המודלים קלי משקל ובעלי זמן תגובה נמוך כדי לאפשר למידת מכונה על גבי המכשיר עצמו. ממיר TensorFlow Lite יוצר קובץ .tflite מתוך SavedModel.
כך, המודל שאימנתי לזיהוי ספרות בכתב יד יכול להישמר ולאחר מכן להיפרס במגוון הקשרים — בין אם כאפליקציית Web שממירה פתקים בכתב יד לדיגיטל, ובין אם כאפליקציית מובייל שמשתמשת במצלמת המכשיר כדי לזהות ספרות בכתב יד בזמן אמת. האפשרויות רבות ומוגבלות רק על ידי הדמיון והיצירתיות.
נכתב על ידי Iryna Engels.