Dans le monde d’aujourd’hui, l’intelligence artificielle est à l’avant-garde de l’innovation technologique, les réseaux de neurones jouant un rôle central dans ce domaine. Les réseaux de neurones, inspirés de la structure biologique du cerveau humain, sont des modèles informatiques puissants capables de résoudre des problèmes complexes en imitant la façon dont les neurones traitent et transmettent l’information. Les applications des réseaux de neurones couvrent un large éventail d’industries, notamment la reconnaissance d’images, le traitement du langage naturel, les voitures autonomes et le diagnostic médical, transformant ainsi notre façon de vivre et de travailler.\r\n\r\nAnimé par ma passion pour la technologie, je n’ai pas pu résister à l’envie d’explorer le potentiel des réseaux de neurones et de l’apprentissage automatique. Cette curiosité m’a conduit à approfondir ce domaine, dans le but de mieux comprendre la théorie et les applications pratiques de ces technologies. Pour commencer, j’ai lu plusieurs articles expliquant les concepts fondamentaux des réseaux de neurones, et après avoir acquis quelques connaissances théoriques, j’ai décidé d’appliquer cette compréhension à un projet pratique. \r\n\r\nDans cet article, je partagerai mon expérience avec les réseaux de neurones, en me concentrant spécifiquement sur le projet que j’ai réalisé, axé sur la reconnaissance de chiffres manuscrits de 0 à 9. \r\n
Description du projet :
\r\nDans ce projet particulier, je me suis concentré sur la reconnaissance de chiffres manuscrits allant de 0 à 9. La reconnaissance de chiffres manuscrits est un problème classique dans le domaine de l’apprentissage automatique et de la vision par ordinateur, servant de point d’entrée pour de nombreux passionnés qui débutent leur parcours dans les réseaux de neurones.\r\n
Les outils et technologies :
\r\nPour créer le réseau de neurones de mon projet de reconnaissance de chiffres manuscrits, j’ai utilisé une variété d’outils et de technologies qui ont facilité le développement et la mise en œuvre du modèle. Voici un aperçu des principales ressources que j’ai utilisées tout au long du projet :\r\n
1. Langage de programmation :
\r\nPython a été mon langage de choix car c’est le langage le plus populaire dans le domaine des réseaux de neurones, offrant ainsi un large support pour les bibliothèques d’apprentissage automatique et de manipulation de données. La large adoption de Python dans la communauté de l’IA garantit également une abondance de ressources et de tutoriels en ligne pour relever divers défis.\r\n
2. Le jeu de données – MNIST :
\r\nPour mon projet, j’ai utilisé le jeu de données MNIST (Modified National Institute of Standards and Technology). Il comprend 70 000 images en niveaux de gris de chiffres manuscrits, chaque image ayant une taille de 28×28 pixels. Le jeu de données est divisé en 60 000 images d’entraînement et 10 000 images de test, ce qui permet un entraînement et une évaluation efficaces des modèles d’apprentissage automatique. Chaque image du jeu de données est étiquetée avec le chiffre correspondant qu’elle représente, allant de 0 à 9\r\n
3. Frameworks :
\r\nJ’ai utilisé TensorFlow et Keras pour construire et entraîner mon réseau de neurones. TensorFlow, développé par Google Brain, est une bibliothèque d’apprentissage automatique open source qui fournit une plateforme flexible pour créer divers types de réseaux de neurones. Keras, quant à lui, est une API de réseau de neurones de haut niveau qui fonctionne sur TensorFlow. Elle simplifie le processus de construction et d’entraînement des réseaux de neurones, le rendant plus accessible aux débutants et permettant un prototypage rapide.\r\n
4. Bibliothèques et packages :
\r\nPour la visualisation des données, j’ai utilisé la bibliothèque Matplotlib.\r\n\r\nL’architecture du modèle :\r\nL’architecture du réseau de neurones pour le projet de reconnaissance de chiffres manuscrits a été conçue pour capturer efficacement les caractéristiques essentielles des images d’entrée tout en maintenant une complexité gérable du modèle. Voici une description des différents composants du modèle :\r\n
1. Couche d’entrée :
\r\nLa couche d’entrée reçoit les images en niveaux de gris de 28×28 pixels des chiffres manuscrits. Ces images sont remodelées en un tenseur 4D avec des dimensions (batch_size, 28, 28, 1) pour répondre aux exigences des couches convolutionnelles.\r\n
2. Couches convolutionnelles :
\r\nLe modèle comporte trois couches convolutionnelles avec des filtres de taille 3×3, et un nombre variable de filtres (32, 64 et 64 respectivement). Ces couches apprennent à extraire des caractéristiques importantes des images, telles que les bords, les courbes et les motifs. Une fonction d’activation ReLU (Rectified Linear Unit) est utilisée dans chacune de ces couches pour introduire de la non-linéarité dans le modèle.\r\n
3. Couches de pooling :
\r\nDeux couches de MaxPooling avec une taille de pool 2×2 sont ajoutées après la première et la deuxième couche convolutionnelle. Ces couches réduisent les dimensions spatiales de l’entrée, aidant le modèle à se concentrer sur les caractéristiques les plus pertinentes tout en réduisant la complexité de calcul et en évitant le surapprentissage.\r\n
4. Couche de mise à plat (Flatten) :
\r\nUne couche Flatten est incluse pour convertir la sortie de la dernière couche convolutionnelle en un tableau 1D, la préparant pour l’entrée dans les couches entièrement connectées.\r\n
5. Couches entièrement connectées (Dense) :
\r\nLe modèle comporte deux couches entièrement connectées. La première couche compte 64 nœuds et utilise une fonction d’activation ReLU pour traiter davantage les caractéristiques extraites. La seconde couche compte 10 nœuds (un pour chaque chiffre de 0 à 9) et utilise une fonction d’activation softmax pour produire des distributions de probabilité pour la classification des chiffres.\r\n
6. Algorithme d’optimisation et fonction de perte :
\r\nPour entraîner le modèle, un optimiseur ‘adam’ est utilisé, qui est un algorithme d’optimisation à taux d’apprentissage adaptatif particulièrement adapté à l’entraînement des réseaux de neurones profonds. La fonction de perte utilisée dans le modèle est ‘categorical_crossentropy’, idéale pour les problèmes de classification multi-classes. Cette fonction de perte calcule l’erreur entre la distribution de probabilité prédite et les étiquettes réelles encodées en one-hot, guidant le modèle pour ajuster ses poids afin de minimiser l’erreur.\r\n\r\n \r\n\r\n \r\n\r\n \r\n\r\nEntraînement et test du modèle :\r\n\r\n
\r\n\r\n \r\n\r\nEntraînement et test du modèle :\r\n\r\n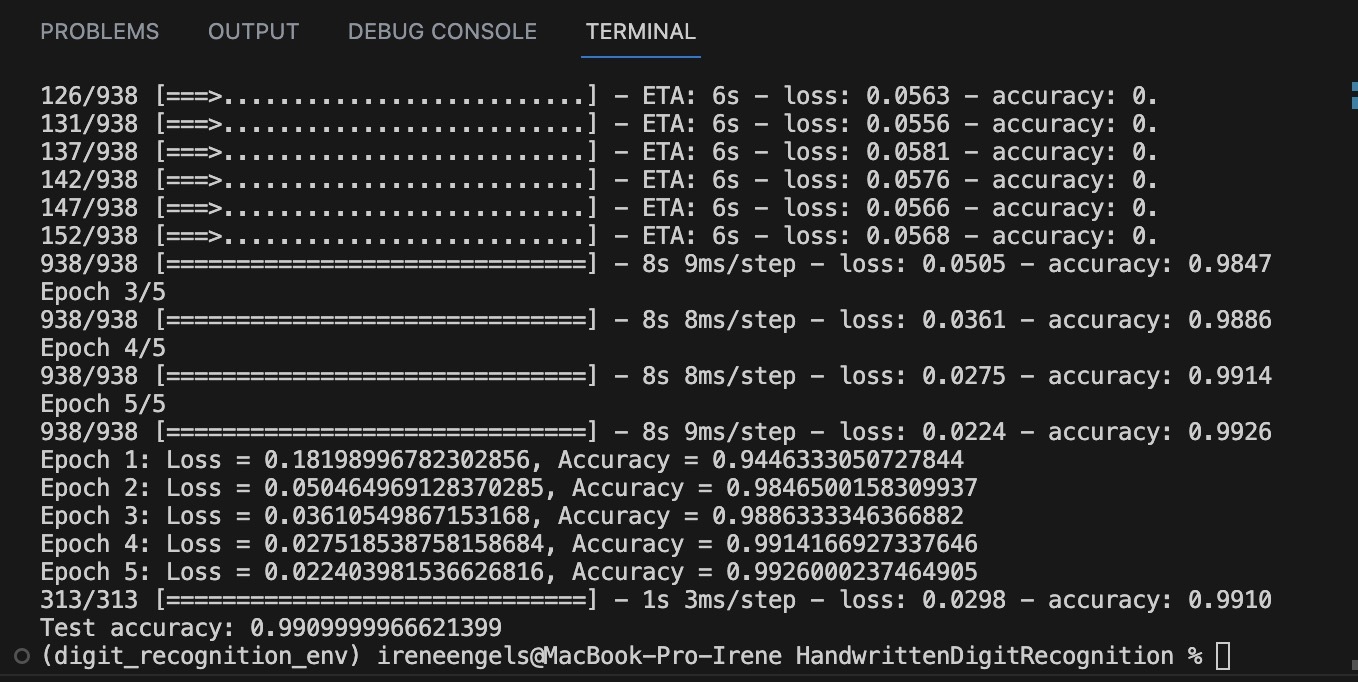 \r\n\r\nAprès avoir préparé les données et conçu l’architecture du modèle, l’étape suivante consistait à entraîner le modèle. Le processus d’entraînement consiste à présenter au modèle les données d’entraînement et à lui permettre de faire des prédictions de manière itérative. Pour chaque prédiction, le modèle calcule l’écart par rapport au résultat réel, à l’aide d’une fonction mathématique appelée « fonction de perte ». Il ajuste ensuite ses paramètres internes de manière à être légèrement moins erroné la prochaine fois.\r\n\r\nDans ce cas, j’ai entraîné le modèle pendant 5 époques. Une époque correspond à un passage complet sur l’ensemble du jeu de données d’entraînement. Chaque époque comportait 938 étapes, correspondant aux 938 lots de 64 images chacun dans les données d’entraînement.\r\n\r\nVoici un résumé de la progression de l’entraînement :\r\n
\r\n\r\nAprès avoir préparé les données et conçu l’architecture du modèle, l’étape suivante consistait à entraîner le modèle. Le processus d’entraînement consiste à présenter au modèle les données d’entraînement et à lui permettre de faire des prédictions de manière itérative. Pour chaque prédiction, le modèle calcule l’écart par rapport au résultat réel, à l’aide d’une fonction mathématique appelée « fonction de perte ». Il ajuste ensuite ses paramètres internes de manière à être légèrement moins erroné la prochaine fois.\r\n\r\nDans ce cas, j’ai entraîné le modèle pendant 5 époques. Une époque correspond à un passage complet sur l’ensemble du jeu de données d’entraînement. Chaque époque comportait 938 étapes, correspondant aux 938 lots de 64 images chacun dans les données d’entraînement.\r\n\r\nVoici un résumé de la progression de l’entraînement :\r\n
- \r\n \t
- Époque 1 : Perte = 0,1783, Précision = 94,57 %
- Époque 2 : Perte = 0,0516, Précision = 98,40 %
- Époque 3 : Perte = 0,0373, Précision = 98,82 %
- Époque 4 : Perte = 0,0282, Précision = 99,09 %
- Époque 5 : Perte = 0,0228, Précision = 99,24 %
\r\n \t
\r\n \t
\r\n \t
\r\n \t
\r\n
\r\nComme vous pouvez le constater, la perte du modèle a diminué à chaque époque, indiquant qu’il devenait meilleur pour prédire les bonnes étiquettes de chiffres à chaque passage sur les données. De même, la précision des prédictions du modèle a augmenté à chaque époque.\r\n\r\nUne fois le modèle entraîné, je l’ai testé sur le jeu de données de test pour évaluer ses performances sur de nouvelles données inédites. La perte sur le jeu de données de test était de 0,0319, et le modèle a atteint une précision de 98,92 %. Cette précision élevée confirme que le modèle a appris à reconnaître efficacement les chiffres manuscrits et a pu bien généraliser des données d’entraînement aux données inédites de l’ensemble de test.\r\n\r\nL’entraînement et le test du modèle ont constitué une étape cruciale du projet. Observer comment le modèle apprenait à partir des données et améliorait ses prédictions à chaque époque était à la fois fascinant et gratifiant. Grâce à mes efforts, je dispose désormais d’un modèle capable de reconnaître avec précision les chiffres manuscrits de 0 à 9.\r\n\r\nUtilisation future et déploiement du modèle entraîné :\r\n\r\nAprès avoir construit et entraîné un modèle capable de reconnaître avec succès les chiffres manuscrits, l’une des prochaines étapes les plus gratifiantes consiste à appliquer ce modèle à des scénarios réels. La polyvalence des modèles d’apprentissage automatique réside dans leur capacité à être sauvegardés, partagés et déployés sur différentes plateformes, étendant ainsi leur utilité au-delà de l’environnement initial dans lequel ils ont été développés.\r\n\r\nDans TensorFlow, vous pouvez sauvegarder l’ensemble du modèle au format HDF5 ou au format SavedModel. Ce dernier est plus complet et comprend un point de contrôle TensorFlow contenant les poids du modèle, ainsi que l’architecture du modèle et la configuration de l’optimiseur. Cela se fait à l’aide de la fonction model.save(). Une fois le modèle sauvegardé, vous pouvez le charger dans un autre script Python (ou même sur une autre machine) et l’utiliser pour faire des prédictions, l’évaluer sur de nouvelles données, ou même poursuivre l’entraînement.\r\n\r\nLa véritable puissance de la sauvegarde des modèles réside cependant dans la possibilité de les déployer dans diverses applications. Par exemple, vous pouvez utiliser votre modèle dans une application Android ou iOS, ou dans une application web, permettant aux utilisateurs d’interagir directement avec lui. Il existe plusieurs façons de procéder.\r\n\r\nPour les applications web, TensorFlow.js peut être utilisé pour charger et exécuter des modèles dans un navigateur. TensorFlow.js fournit des utilitaires pour sauvegarder et charger des modèles directement depuis le LocalStorage ou l’IndexedDB des navigateurs. Les modèles peuvent également être servis depuis un serveur HTTP/HTTPS statique, ou depuis des plateformes de stockage cloud comme Google Cloud Storage.\r\n\r\nPour les applications mobiles, TensorFlow Lite permet de déployer des modèles TensorFlow sur des appareils mobiles et IoT. Les modèles sont légers et présentent une faible latence pour permettre l’apprentissage automatique sur l’appareil. Le convertisseur TensorFlow Lite crée un fichier .tflite à partir d’un SavedModel.\r\n\r\nAinsi, le modèle que j’ai entraîné pour la reconnaissance de chiffres manuscrits peut être sauvegardé puis déployé dans divers contextes – qu’il s’agisse d’une application web qui numérise des notes manuscrites, ou d’une application mobile qui utilise la caméra d’un appareil pour reconnaître des chiffres manuscrits en temps réel. Les possibilités sont nombreuses et ne sont limitées que par l’imagination et l’ingéniosité de chacun.\r\n\r\nRédigé par Iryna Engels.